
I’ve pushed several files to the class repo, including two programs to help you visualize the embeddings in your corpus: interact_cooccur.py, which we played with in class on Tuesday, and visualize_cooccur.py, which can produce 2-d (and even 3-d) plots like this showing the embeddings in a reduced-dimensional space:
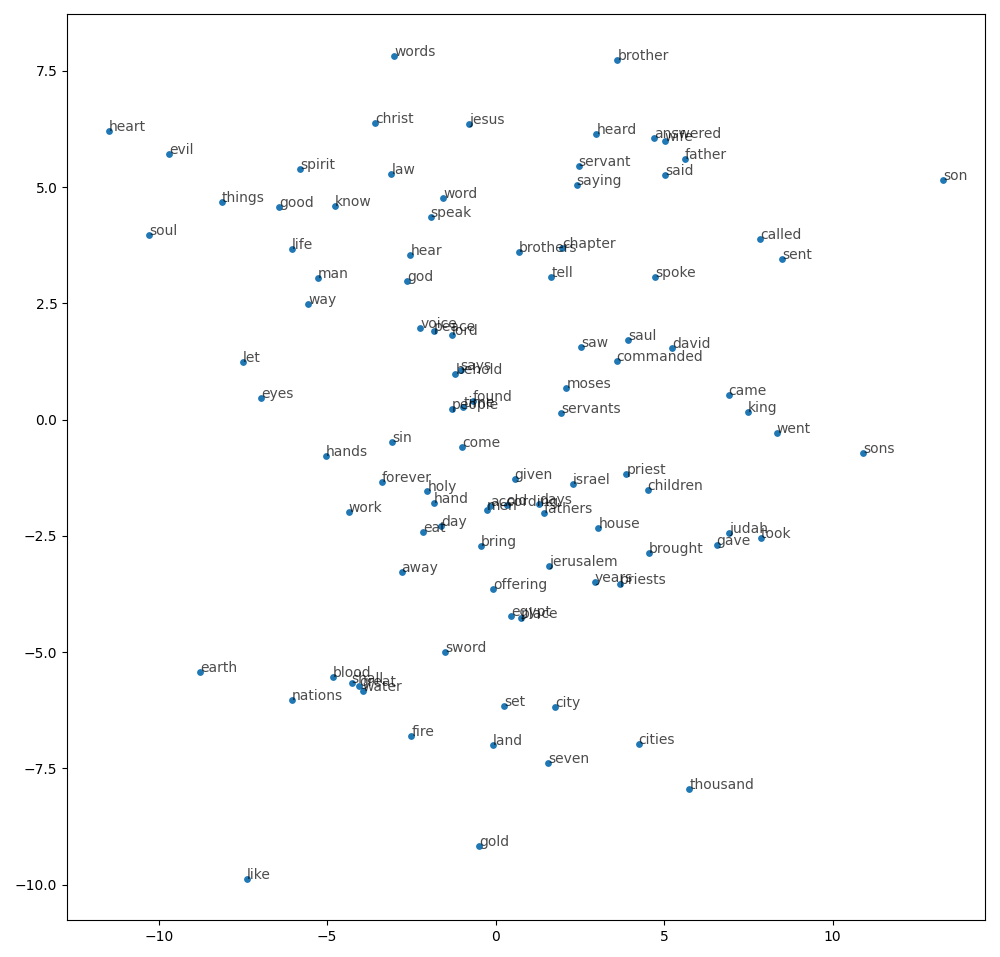
The next homework assignment (coming soon) will have you running and configuring these programs to help you analyze your own corpus’s embeddings. Stay tuned for that.
Also, I have posted the code we used to play around with standard pre-trained embedding collections (like word2vec and GloVe): you’ll need to first run the download_embeddings.py file (while connected to a good network) and then run either sim_emb_play.py or closest_emb_play.py to find the similarity of pairs of words, or the top-10 closest embeddings to a given word, respectively.
