DATA 419 — NLP — Fall 2025
Possible experience: +40XP
Due: Fri Oct 17th, midnight
There are two parts to this assignment, each worth up to +20XP:
Obtain the file pytorch_practice.py from the class github repo. (The cool way to do this, if you've worked with git and github before, is to first clone the repo, and then simply cd (or your operating system's equivalent) into its directory. pytorch_practice.py, and everything else from the class, will be right there. Any time I announce that I've updated the repo, you can just "git pull" to get the new contents. The not-so-cool way to do this is to navigate to the repo's contents in your browser, click on the pytorch_practice.py file, and copy/paste its contents into a new text file on your machine.)
Copy this file to a new name: yourumwuserid_pytorch_practice.py. (Please replace "yourumwuserid" with your actual UMW user ID. For instance, "tswift22_pytorch_practice.py" would be an appropriate name. Please do not deviate from this naming convention in any way. Please do not get clever, or creative, or include capital letters, or change the file extension, or omit the underscores, or replace the underscores with hyphens, or anything else counter to the above instructions. Please name your file exactly as above. Thanks.)
Run this Python file, and make sure that it runs and prints out "You got +0XP! (out of a possible 20XP)" message at the end. If it gives you an error instead, read the error. One strong possibility is that you may not have installed pytorch on your machine ("pip install torch"). Use a combination of your brain, Google, ChatGPT, fellow classmates, and Stephen, to figure out how to get it installed, rectify any other errors, and get the program to run with that "+0XP" message at the end.
Once it's running and gives you that message, open the yourumwuserid_pytorch_practice.py file in your editor and begin reading. There are 20 items, each of which require you to write a little code. You can re-run the program at any time to see what your current score is. Keep going until you're done! (Use the same 5 resources as listed above to figure out any incorrect answers you're getting.)
Obtain these files from the class git repo:
(If you cloned the git repo, as described above, those files are already right there in your current directory. Otherwise, you can copy/paste from the repo as described above.)
Make sure you've installed the spaCy Python package, since I use it for tokenizing. ("pip install spacy" is the normal procedure, followed by running "python -m spacy download en_core_web_sm" at the command line. You'll only ever have to do this once this semester.)
Also be sure to pip install the following packages:
Then, take it for a whirl:
$ python interact_cooccur.py syllabus.tex
syllabus.tex is simply our class syllabus, in its raw (LaTeX) form. Running the code above should complete very quickly, and give you a prompt like this:
2,156 tokens. 771 types. The matrix is size 632x632 with 2808 entries (0.7% full) Enter a word (or 'ex' for examples, or 'done'):
This output means my code found 2,156 tokens in the syllabus, 771 of which were unique. It built a square matrix of length/width 632 for the 632 most-common-but-not-too-common words, and that matrix is 99.3% zeroes (i.e., the vast majority of word pairs did not occur together in the same context window. This is very typical of text corpora, as we know.)
You can type ex to randomly sample words from the corpus:
Enter a word (or 'ex' for examples, or 'done'): ex Here are some common words in the corpus: (1) accomplish (2) classification (3) format (4) glacial (5) group (6) legends (7) maintained (8) shakespeare (9) xp (10) strikes Choose one:
Let's look at Shakespeare:
Enter a word (or 'ex' for examples, or 'done'): 8 Most/least similar words to SHAKESPEARE: shape: (21, 2) ┌────────────┬────────────┐ │ word ┆ similarity │ │ --- ┆ --- │ │ str ┆ f64 │ ╞════════════╪════════════╡ │ william ┆ 0.6 │ │ homer ┆ 0.6 │ │ grade ┆ 0.516398 │ │ mid ┆ 0.474342 │ │ hesitate ┆ 0.447214 │ │ awarded ┆ 0.447214 │ │ highlight ┆ 0.447214 │ │ dostoevsky ┆ 0.4 │ │ level ┆ 0.4 │ │ grading ┆ 0.316228 │ │ -------- ┆ null │ │ cpsc ┆ 0.0 │ │ reviewing ┆ 0.0 │ │ tensors ┆ 0.0 │ │ matrices ┆ 0.0 │ │ computer ┆ 0.0 │ │ warning ┆ 0.0 │ │ needs ┆ 0.0 │ │ mind ┆ 0.0 │ │ plan ┆ 0.0 │ │ review ┆ 0.0 │ └────────────┴────────────┘
The output is just like the Bible example from class -- it shows the ten words that are most similar, and the ten least similar, to shakespeare. Let's try XP as another example:
Enter a word (or 'ex' for examples, or 'done'): xp Most/least similar words to XP: shape: (21, 2) ┌─────────────┬────────────┐ │ word ┆ similarity │ │ --- ┆ --- │ │ str ┆ f64 │ ╞═════════════╪════════════╡ │ possible ┆ 0.324102 │ │ activity ┆ 0.280056 │ │ activities ┆ 0.257248 │ │ exam ┆ 0.255261 │ │ based ┆ 0.242536 │ │ shakespeare ┆ 0.230089 │ │ version ┆ 0.230089 │ │ level ┆ 0.230089 │ │ linear ┆ 0.210042 │ │ davies ┆ 0.210042 │ │ -------- ┆ null │ │ mind ┆ 0.0 │ │ need ┆ 0.0 │ │ background ┆ 0.0 │ │ build ┆ 0.0 │ │ qsc ┆ 0.0 │ │ assigning ┆ 0.0 │ │ surgically ┆ 0.0 │ │ daniel ┆ 0.0 │ │ release ┆ 0.0 │ │ vectors ┆ 0.0 │ └─────────────┴────────────┘
Etc.
If you run the program with a -h option:
$ run interact_cooccur.py -h
usage: interact_cooccur.py [-h] [--matrix-type {counts,ppmi}]
[--max-vocab MAX_VOCAB] [--window-size WINDOW_SIZE]
[--verbose] [--cached] [--n N]
[--dimensions DIMENSIONS]
inputfile
Interact with terms in a manually computed co-occurrence matrix.
positional arguments:
inputfile Path to input file from which to compute co-occurrence
matrix
options:
-h, --help show this help message and exit
--matrix-type {counts,ppmi}
Which kind of co-occurrence matrix to build
--max-vocab MAX_VOCAB
Maximum number of vocab words to keep (based on
frequency)
--window-size WINDOW_SIZE
Size of window, to left and right of a token (default
+/-3)
--verbose Verbose output during computation
--cached Use previously cached matrix/vocab if available
--n N Number of most, and least, similar words to display
--dimensions DIMENSIONS
Dimensions of word embeddings (if this is 0, use PPMI
directly)
you'll see a number of options I've added. Using ppmi (PPMI) instead of counts (TF-IDF) will be a bit slower but possibly a bit better; lowering the max-vocab (number of words to keep) will help a lot with speeding it up. Playing with the window-size will also change the nature of the embeddings, as we discussed in class.
Run the program on your own corpus file, substituting its name for syllabus.tex.
If your corpus is pretty large, you may want to switch to using "--matrix-type counts" and/or a smaller vocab size like "--max-vocab 200" and/or a smaller context window like "--max-vocab 2". Experimentation and patience are what's called for here.
Spend some significant time playing with the program to see which words are considered closer to which other words. Does it align with your intuition? Does changing the type of matrix, or the context window size, change things, and if so, how?
Choose a small number of words that had interesting similarities, and copy from your screen output like in the listings above. Explain in a paragraph or two why these results did, or did not, line up with your intuition. Then write at least one thoughtful paragraph about what you learned about your corpus and about embeddings through the interactive process.
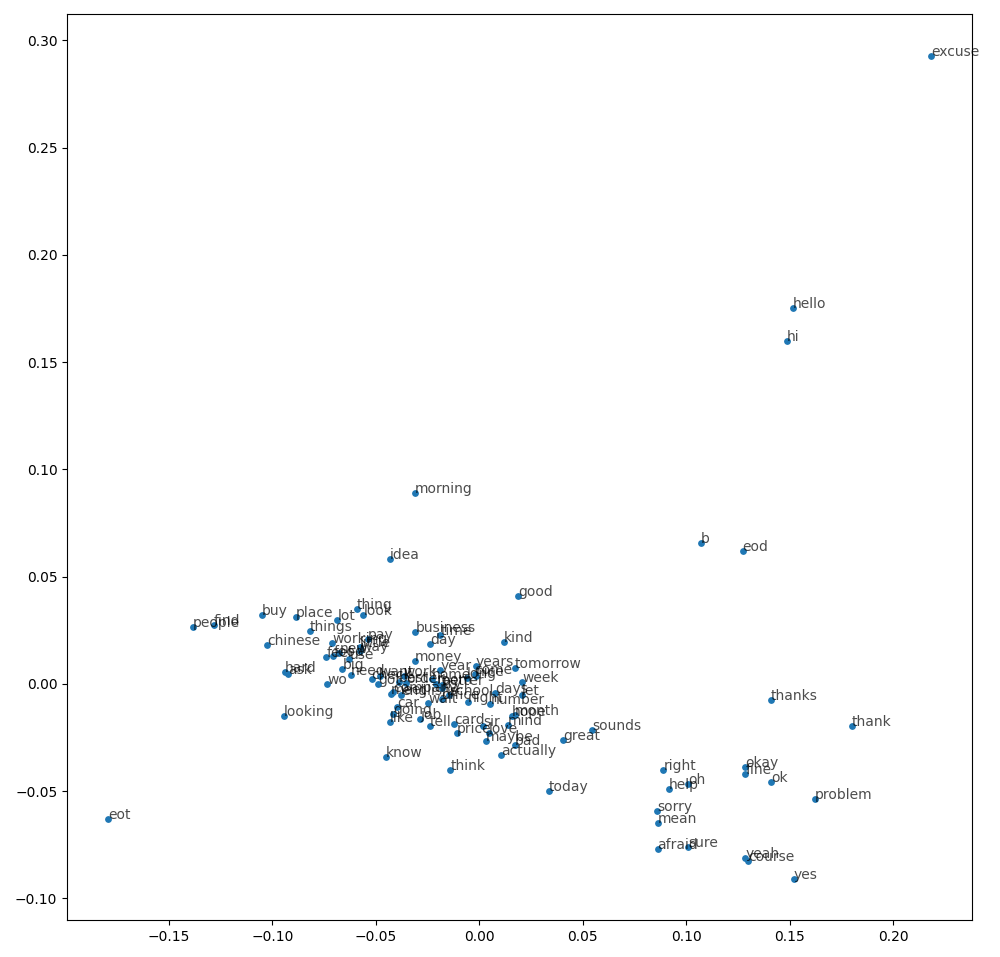
Substitute the word "visualize" for the word "interact" in the program's name (keeping all the other settings is fine) and you'll get a 2-d plot showing a dimensionally-reduced projection of the embeddings onto a flat space. Here's the result for the daily dialog corpus, often used to train chatbots:
If you add a "--dimensions 3" argument when you run it, you'll instead get a 3-d projection that you can click on and maneuver.
Save the 2-d plot to a file (there should be a "diskette" button you can click on to save), and then write at least one thoughtful paragraph about what you learned about your corpus and about embeddings through the visualization process.
For this assignment, send an email with subject line "DATA 470 Homework #3 turnin," and with these contents:
Come to office hours, or send me email with subject line "DATA 470 Homework #3 help!!"